续上一篇文章的算法,这次自己改成PHP版本,当然如果有优化的地方请指出,以便大家学习。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76<?php
header('Content-Type: text/html; charset=UTF-8');
$text1 = <<<EOF
Fragment A (By Rousseau):
À l’instant, au lieu de la personne particulière de chaque contractant, cet acte d’association produit un Corps moral et collectif, composé d’autant de membres que l’assemblée a de voix, lequel reçoit de ce même acte son unité, son moi commun, sa vie et sa volonté. Cette personne publique, qui se forme ainsi par l’union de toutes les autres, prenait autrefois le nom de Cité , et prend maintenant celui de République ou de Corps politique: lequel est appelé par ses membres État quand il est passif, Souverain quand il est actif, Puissance en le comparant à ses semblables. À l’égard des associés, ils prennent collectivement le nom de peuple, et s’appellent en particulier citoyens, comme participant à l’autorité souveraine, et sujets, comme soumis aux lois de l’État. (Rousseau, Du contrat social, I.6)
EOF;
$text2 = <<<EOF
Fragment B (By Hobbes):
Art goes yet further, imitating that Rationall and most excellent worke of Nature, Man. For by Art is created that great LEVIATHAN called a COMMON-WEALTH, or STATE, (in latine CIVITAS) which is but an Artificiall Man; though of greater stature and strength than the Naturall, for whoseprotection and defence it was intended; and in which, the Soveraignty is an Artificiall Soul, as giving life and motion to the whole body; The Magistrates, and other Officers of Judicature and Execution, artificiall Joynts; Reward and Punishment (by which fastned to the seat of the Soveraignty, every joynt and member is moved to performe his duty) are the Nerves, that do the same in the Body Naturall; The Wealth and Riches of all the particular members, are the Strength; Salus Populi (the Peoples Safety) its Businesse; Counsellors, by whom all things needfull for it to know, are suggested unto it, are the Memory; Equity and Lawes, an artificiall Reason and Will; Concord, Health; Sedition, Sicknesse; and Civill War, Death. Lastly, the Pacts and Covenants, by which the parts of this Body Politique were at first made, set together, and united, resemble that Fiat, or the Let Us Make Man, pronounced by God in the Creation. (Hobbes, Leviathan, "Introduction")
EOF;
echo similarAlgorithm($text1 , $text2);
/*
* 文本相似度匹配
* @author juice
* @param text1 匹配文本1
* @param text2 匹配文本2
* @return double 返回相似度(余弦值)
*/
function similarAlgorithm($text1 = '' , $text2 = ''){
$charset = 'UTF-8' ;
$text1Array = mbStringToArray($text1 , $charset ,TRUE);
$text2Array = mbStringToArray($text2 , $charset ,TRUE);
$textSumArray = array();
foreach($text1Array as $key => $val){//统计该字在第一文本中出现的次数
if(isset($textSumArray[$val])){
$textSumArray[$val][0]++;
} else {
$textSumArray[$val][0] = 1;
$textSumArray[$val][1] = 0;
}
}
foreach($text2Array as $key => $val){//统计该字在第二文本中出现的次数
if(isset($textSumArray[$val])){
$textSumArray[$val][1]++;
}else {
$textSumArray[$val][0] = 0;
$textSumArray[$val][1] = 1;
}
}
$sqdoc1 = 0;//平方和
$sqdoc2 = 0;//平方和
$denominator = 0;
foreach($textSumArray as $key => $val){
$denominator += $val[0] * $val[1];
$sqdoc1 += $val[0] * $val[0];
$sqdoc2 += $val[1] * $val[1];
}
return $denominator / sqrt($sqdoc1*$sqdoc2);
}
/*
* 分割字符串方法 (支持中文分割)
* @author juice
* @param str 需要分割的字符串
* @param charset 字符串的编码,默认UTF-8
* @param convertedToHex 是否返回该字符的16进制,TRUE返回每个字符16进制,FALSE则返回原本字符
* @return double 返回相似度(余弦值)
*/
function mbStringToArray($str = '',$charset = 'UTF-8' , $convertedToHex = FALSE) {
$strlen = mb_strlen($str);
if( $convertedToHex === TRUE ){
while($strlen){
$array[] = bin2hex(mb_substr($str,0,1,$charset));
$str = mb_substr($str,1,$strlen,$charset);
$strlen = mb_strlen($str);
}
}else{
while($strlen){
$array[] = mb_substr($str,0,1,$charset);
$str = mb_substr($str,1,$strlen,$charset);
$strlen = mb_strlen($str);
}
}
return $array;
}
?>
php curl请求返回400 Bad Request的解决方法
1 | |
当你使用php的curl方法时会返回400 Bad Request,这有如下几种原因:
1.远端有检测客户端过滤行为。
2.远端有redir行为。
3.请求中间层。
4.近端有过滤行为。
5.某个过程有缓存机制。
6.脚本文件编码问题。
前面5种都是服务器的限制,做一些伪装就可以,但是很多人会忽略掉第六个原因,这是因为Unicode、Unicode big endian和UTF-8编码的txt文件的开头会多出几个字节,分别是FF、FE(Unicode),FE、FF(Unicode big endian),EF、BB、BF(UTF-8)。一般只要换成UTF-8编码就没有可以解决了。
看我如何劫持用户的浏览器
标题起的有点大有点夸张,但应该引起重视,起因是我在搜索一个东西的时候,打开了一个垃圾站点,神奇的事情发生了,新标签打开这个站点后,我的Google搜索页面自动跳转到广告页面了,出于好奇必须研究一下,首先它控制了我的Google搜索页面,所以我猜测它代码里有“Google”这个关键词,在Chrome控制台用强大的ctrl+shift+f搜到了几个js文件,前面都是Google广告的js,最后一个js.js是咸鱼饭,于是在这个文件里找到可疑的被加密的代码位置下了个断点。

经过耐心一直按F11跟踪后,控制台VM输出了解密后的关键函数。
看到这里基本上就知道了垃圾站劫持搜索页面的方法了,代码很简单有点基础的同学应该都可以看懂,这时我的想法是这么简单,我怎么没想到,思路很重要,到这里代码分析及实现原理就这样完了,简单到没什么可以讲的了。
垃圾站用这样的方式来刷流量刷广告很正常,但是我想到的是更可怕的事情,被访问页面可以劫持用户的来源页面,也就产生了一个钓鱼攻击的利用场景:
1,用户A在微博看到一个链接好奇打开了;
2,被打开的页面evilA用一些吸引眼球的内容抓住用户的注意力;
3,微博页面被劫持跳转到钓鱼页面,例如一个假的高仿的微博页面evilB;
4,当用户关闭页面evilA,打算继续看微博的时候,此时他看到的是高仿的微博页面evilB,而用户没留意到页面已经被替换;
5,高仿的微博页面evilB提示登录超时,要求用户重新登录,用户输入帐号密码;
6,高仿的微博页面evilB记录用户密码后再跳回正常的微博页面,用户帐号在不知不觉中被盗;
测试页面:http://wanz.im/demo/referrer-hijacking.html
Chrome 28.0.1500.72 m,Firefox 22.0成功劫持,IE 10.0.9200.16635提示没有权限
当然上述是理想状态下的钓鱼攻击,高端点的利用就是程序通过referrer信息立刻生成一个相同的页面来钓鱼,不注意防范依然有风险存在,上网需谨慎!
浅谈CSRF攻击方式
一.CSRF是什么?
CSRF(Cross-site request forgery),中文名称:跨站请求伪造,也被称为:one click attack/session riding,缩写为:CSRF/XSRF。
二.CSRF可以做什么?
你这可以这么理解CSRF攻击:攻击者盗用了你的身份,以你的名义发送恶意请求。CSRF能够做的事情包括:以你名义发送邮件,发消息,盗取你的账号,甚至于购买商品,虚拟货币转账……造成的问题包括:个人隐私泄露以及财产安全。
三.CSRF漏洞现状
CSRF这种攻击方式在2000年已经被国外的安全人员提出,但在国内,直到06年才开始被关注,08年,国内外的多个大型社区和交互网站分别爆出CSRF漏洞,如:NYTimes.com(纽约时报)、Metafilter(一个大型的BLOG网站),YouTube和百度HI……而现在,互联网上的许多站点仍对此毫无防备,以至于安全业界称CSRF为“沉睡的巨人”。
四.CSRF的原理
下图简单阐述了CSRF攻击的思想:

从上图可以看出,要完成一次CSRF攻击,受害者必须依次完成两个步骤:
1.登录受信任网站A,并在本地生成Cookie。
2.在不登出A的情况下,访问危险网站B。
看到这里,你也许会说:“如果我不满足以上两个条件中的一个,我就不会受到CSRF的攻击”。是的,确实如此,但你不能保证以下情况不会发生:
1.你不能保证你登录了一个网站后,不再打开一个tab页面并访问另外的网站。
2.你不能保证你关闭浏览器了后,你本地的Cookie立刻过期,你上次的会话已经结束。(事实上,关闭浏览器不能结束一个会话,但大多数人都会错误的认为关闭浏览器就等于退出登录/结束会话了……)
3.上图中所谓的攻击网站,可能是一个存在其他漏洞的可信任的经常被人访问的网站。
上面大概地讲了一下CSRF攻击的思想,下面我将用几个例子详细说说具体的CSRF攻击,这里我以一个银行转账的操作作为例子(仅仅是例子,真实的银行网站没这么傻:>)
示例1:
银行网站A,它以GET请求来完成银行转账的操作,如:http://www.mybank.com/Transfer.php?toBankId=11&money=1000
危险网站B,它里面有一段HTML的代码如下:
首先,你登录了银行网站A,然后访问危险网站B,噢,这时你会发现你的银行账户少了1000块……
为什么会这样呢?原因是银行网站A违反了HTTP规范,使用GET请求更新资源。在访问危险网站B的之前,你已经登录了银行网站A,而B中的图以GET的方式请求第三方资源(这里的第三方就是指银行网站了,原本这是一个合法的请求,但这里被不法分子利用了),所以你的浏览器会带上你的银行网站A的Cookie发出Get请求,去获取资源“http://www.mybank.com/Transfer.php?toBankId=11&money=1000”,结果银行网站服务器收到请求后,认为这是一个更新资源操作(转账操作),所以就立刻进行转账操作……
示例2:
为了杜绝上面的问题,银行决定改用POST请求完成转账操作。
银行网站A的WEB表单如下:
1 | <form action="Transfer.php" method="POST"> |
后台处理页面Transfer.php如下:
1 | <?php |
危险网站B,仍然只是包含那句HTML代码:
和示例1中的操作一样,你首先登录了银行网站A,然后访问危险网站B,结果…..和示例1一样,你再次没了1000块~T_T,这次事故的原因是:银行后台使用了$_REQUEST去获取请求的数据,而$_REQUEST既可以获取GET请求的数据,也可以获取POST请求的数据,这就造成了在后台处理程序无法区分这到底是GET请求的数据还是POST请求的数据。在PHP中,可以使用$_GET和$_POST分别获取GET请求和POST请求的数据。在JAVA中,用于获取请求数据request一样存在不能区分GET请求数据和POST数据的问题。
示例3:
经过前面2个惨痛的教训,银行决定把获取请求数据的方法也改了,改用$_POST,只获取POST请求的数据,后台处理页面Transfer.php代码如下:
1 | <?php |
然而,危险网站B与时俱进,它改了一下代码:
1 | <html> |
如果用户仍是继续上面的操作,很不幸,结果将会是再次不见1000块……因为这里危险网站B暗地里发送了POST请求到银行!
总结一下上面3个例子,CSRF主要的攻击模式基本上是以上的3种,其中以第1,2种最为严重,因为触发条件很简单,一个就可以了,而第3种比较麻烦,需要使用JavaScript,所以使用的机会会比前面的少很多,但无论是哪种情况,只要触发了CSRF攻击,后果都有可能很严重。
理解上面的3种攻击模式,其实可以看出,CSRF攻击是源于WEB的隐式身份验证机制!WEB的身份验证机制虽然可以保证一个请求是来自于某个用户的浏览器,但却无法保证该请求是用户批准发送的!
五.CSRF的防御
我总结了一下看到的资料,CSRF的防御可以从服务端和客户端两方面着手,防御效果是从服务端着手效果比较好,现在一般的CSRF防御也都在服务端进行。
1.服务端进行CSRF防御
服务端的CSRF方式方法很多样,但总的思想都是一致的,就是在客户端页面增加伪随机数。
(1).Cookie Hashing(所有表单都包含同一个伪随机值):
这可能是最简单的解决方案了,因为攻击者不能获得第三方的Cookie(理论上),所以表单中的数据也就构造失败了:>
1 | <?php |
在表单里增加Hash值,以认证这确实是用户发送的请求。
1 | <?php |
然后在服务器端进行Hash值验证
1 | <?php |
这个方法个人觉得已经可以杜绝99%的CSRF攻击了,那还有1%呢….由于用户的Cookie很容易由于网站的XSS漏洞而被盗取,这就另外的1%。一般的攻击者看到有需要算Hash值,基本都会放弃了,某些除外,所以如果需要100%的杜绝,这个不是最好的方法。
(2).验证码
这个方案的思路是:每次的用户提交都需要用户在表单中填写一个图片上的随机字符串,厄….这个方案可以完全解决CSRF,但个人觉得在易用性方面似乎不是太好,还有听闻是验证码图片的使用涉及了一个被称为MHTML的Bug,可能在某些版本的微软IE中受影响。
(3).One-Time Tokens(不同的表单包含一个不同的伪随机值)
在实现One-Time Tokens时,需要注意一点:就是“并行会话的兼容”。如果用户在一个站点上同时打开了两个不同的表单,CSRF保护措施不应该影响到他对任何表单的提交。考虑一下如果每次表单被装入时站点生成一个伪随机值来覆盖以前的伪随机值将会发生什么情况:用户只能成功地提交他最后打开的表单,因为所有其他的表单都含有非法的伪随机值。必须小心操作以确保CSRF保护措施不会影响选项卡式的浏览或者利用多个浏览器窗口浏览一个站点。
以下我的实现:
1).先是令牌生成函数(gen_token()):
1 | <?php |
2).然后是Session令牌生成函数(gen_stoken()):
1 | <?php |
3).WEB表单生成隐藏输入域的函数:
1 | <?php |
4).WEB表单结构:
1 | <?php |
5).服务端核对令牌:
这个很简单,这里就不再啰嗦了。
上面这个其实不完全符合“并行会话的兼容”的规则,大家可以在此基础上修改。
转载请说明出处,谢谢[hyddd(http://www.cnblogs.com/hyddd/)]
URL处理的两个关键PHP函数parse_str与http_build_query
简单的理解这两个函数
parse_str就是将一个url ?后面的参数转换成一个数组
array parse_str(url,arr)
http_build_query就是将一个数组转换成url ?后面的参数字符串,会自动进行urlencode处理
string http_build_query ( array formdata [, string numeric_prefix])
后面的给数组中没有指定键或者键为数字的加下标
我们知道, PHP的 parse_str() 函数可以将 URL Query 格式的字符串解析成关联数组, 与PHP生成 $_GET 使用的相同的策略. parse_str() 的”反函数”是 http_build_query(), 它将关联数组和对象生成 URL Query 字符串. 不过, 只在PHP5之后才被支持. 所以, 我们需要编写自己的 http_build_query()
1 | function my_http_build_query($data) { |
php 模拟新浪微博oauth2.0授权获取access_token (跳过授权页)(改)
1 | <? |
我们可以再输出中看到返回的access_token、uid等数据,并且查看该微博已经授权appkey对应的应用。这段代码其实没有什么很大作用,因为还不能自动授权,不过还可以制作自己的微博授权登录界面。如有问题可留言给我,记得留下你的邮箱方便回复。
本文参考http://hi.baidu.com/bing008ok/item/0a2bce068d1f8e0aeafe385d
实现文本相似度算法(余弦定理)(转)
最近由于工作项目,需要判断两个txt文本是否相似,于是开始在网上找资料研究,因为在程序中会把文本转换成String再做比较,所以最开始找到了这篇关于 距离编辑算法 Blog写的非常好,受益匪浅。
于是我决定把它用到项目中,来判断两个文本的相似度。但后来实际操作发现有一些问题:直接说就是查询一本书中的相似章节花了我7、8分钟;这是我不能接受……
于是停下来仔细分析发现,这种算法在此项目中不是特别适用,由于要判断一本书中是否有相同章节,所以每两个章节之间都要比较,若一本书书有x章的话,这里需对比x(x-1)/2次;而此算法采用矩阵的方式,计算两个字符串之间的变化步骤,会遍历两个文本中的每一个字符两两比较,可以推断出时间复杂度至少为document1.length × document2.length,我所比较的章节字数平均在几千~一万字;这样计算实在要了老命。
想到Lucene中的评分机制,也是算一个相似度的问题,不过它采用的是计算向量间的夹角(余弦公式),在google黑板报中的:数学之美(余弦定理和新闻分类) 也有说明,可以通过余弦定理来判断相似度;于是决定自己动手试试。
首相选择向量的模型:在以字为向量还是以词为向量的问题上,纠结了一会;后来还是觉得用字,虽然词更为准确,但分词却需要增加额外的复杂度,并且此项目要求速度,准确率可以放低,于是还是选择字为向量。
然后每个字在章节中出现的次数,便是以此字向量的值。现在我们假设:
章节1中出现的字为:Z1c1,Z1c2,Z1c3,Z1c4……Z1cn;它们在章节中的个数为:Z1n1,Z1n2,Z1n3……Z1nm;
章节2中出现的字为:Z2c1,Z2c2,Z2c3,Z2c4……Z2cn;它们在章节中的个数为:Z2n1,Z2n2,Z2n3……Z2nm;
其中,Z1c1和Z2c1表示两个文本中同一个字,Z1n1和Z2n1是它们分别对应的个数,
最后我们的相似度可以这么计算: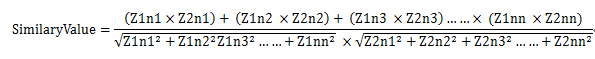
程序实现如下:(若有可优化或更好的实现请不吝赐教)
1 | public class CosineSimilarAlgorithm { |
程序中做了两小的改进,以加快效率:
- 只将汉字作为向量,其他的如标点,数字等符号不处理;2. 在HashMap中存放汉字和其在文本中对于的个数时,先将单个汉字通过GB2312编码转换成数字,再存放。
最后写了个测试,根据两种不同的算法对比下时间,下面是测试结果:
余弦定理算法:doc1 与 doc2 相似度为:0.9954971, 耗时:22mm
距离编辑算法:doc1 与 doc2 相似度为:0.99425095, 耗时:322mm
可见效率有明显提高,算法复杂度大致为:document1.length + document2.length。
第一天
2013年08月25日。第一天写博客,主要是想在这里与大家分享个人工作心得和经验,以及分享一些比较有趣的东西。本人能力有限,如对博文有何建议或者错误请您谅解并留下您的脚印。谢谢!
Juice
2013年08月25日